




Up until this point in our R&D series, we’ve focused on the techniques for creating high-quality 3D reconstructions. While we still wrestle with the challenges we discussed in previous posts, let’s dive into the technical details of one of the cool things we can do once we have a good reconstruction of a street. Let’s dive into locationization of objects in the scene.
Street signs are an important city asset, helping to coordinate drivers, pedestrians, and others on the street. Their standard shapes, sizes, and colors help people (and even computers) easily find them in visually complex scenes.
The latest machine learning algorithms are quite adept at finding street signs in an image and, by providing a consistent pattern across multiple images, street signs are even helpful as anchor points for the SLAM techniques we use to create 3D reconstructions.
However, this uniformity has some drawbacks. Simply identifying a street sign in an image, even when the image has a GPS stamp, doesn’t tell you the location of the street sign in the real world.
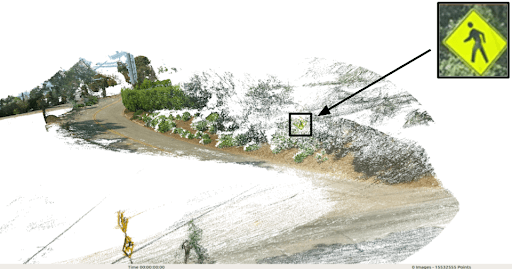
As an example, take the image above. Knowing the GPS coordinates of the camera when this photo was taken is useful (though not exact) for stamping the location of the street signs attached to the traffic light pole. But for the street sign in the bottom left corner, this photo is too far away for it to be a good proxy. Other photos of that street sign that are closer to it will certainly be better proxies for the GPS location of the sign, but how can we know that the speed limit sign in those photos is the same one we see here? All 30-mph speed limit signs in any single city tend to look the same.
The GPS locations of the photos in question can help disambiguate if two photos are looking at the same street sign, but there are plenty of cases where two street signs are so close together that GPS alone is not accurate enough (see the example in the photo above).
However, if we have a 3D reconstruction of a street, we can pin-point the location of each sign in the reconstruction relative to the position and orientation of the camera for each photo used in the reconstruction. Let’s show an example.
In the series below, we see several photos of a pedestrian crossing street sign, one that is getting closer as the car in which the camera is mounted makes a turn.
If you look very closely, you can even see a bounding box around the sign in each photo. This is the automatic street sign detection performed by a deep learning algorithm. Although it may be obvious to us, it is not trivial for a computer to say that all of these photos are of the exact same street sign.
So, we create a 3D reconstruction using these photos, along with the ones before and after, too. Now with only one street sign in the reconstruction, we can be certain that the signs identified above all are indeed the same one.
On top of that, we also now know the location of the street sign with respect to the positions and orientations of the camera in each photo. Using this information and the GPS coordinates of the camera in each photo, we can calculate the location of the sign with much higher accuracy than simply assigning it the location of one of the photos.
Now, what happens if the 3D reconstruction produced by SLAM doesn’t contain the street sign (or some other asset) that we want to locate? Modern SLAM still relies on some amount of random point selection in each photo, and there is a not-insignificant chance that the asset of interest doesn’t end up in the final reconstruction.
Even in this case, as long as we can mark the asset of interest with a bounding box in a few photos used for the reconstruction, we can project those bounding boxes out into 3D space (as a rectangular 3D box, kind of like a french fry that expands in width as it extends away from the camera) and use the intersection of those boxes as an approximate location for the asset of interest.
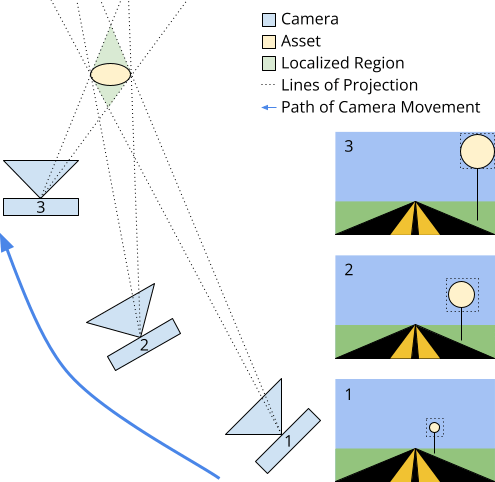
To help visualize this, see the photo on the left. From a top-down view, imagine a camera moving along the path of the blue arrow.
Using a 3D reconstruction, we can determine the location and orientation of the camera at a few different points in time. Then, in the photograph taken at each of these locations, we can draw a bounding box around the asset (the yellow circle) we want to locate in 3D space. We then project that bounding box out of the photo, into the 3D world along the lines of projection, and use the intersection of these projections to find an approximate location for the asset in the 3D world. The localization region will almost certainly be larger than the asset itself, but it still serves as a better location marker than simply using the location of one of the cameras that captured the asset.
As always, stay tuned for the next post in our Research and Development blog series!

© 2023 RoadBotics, Inc | 322 North Shore Drive, Suite 200, Pittsburgh, PA 15212
| Cookie | Duration | Description |
|---|---|---|
| __hssrc | session | This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session. |
| _GRECAPTCHA | 5 months 27 days | This cookie is set by the Google recaptcha service to identify bots to protect the website against malicious spam attacks. |
| ak_bmsc | 2 hours | This cookie is used by Akamai to optimize site security by distinguishing between humans and bots |
| citrix_ns_id | session | This cookie is set by the provider Citrix, a web application firewall. This cookie is used for protecting the website against known and unknown attacks. |
| cookielawinfo-checkbox-advertisement | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category . |
| cookielawinfo-checkbox-analytics | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Analytics" category . |
| cookielawinfo-checkbox-functional | 1 year | The cookie is set by the GDPR Cookie Consent plugin to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Necessary" category . |
| cookielawinfo-checkbox-others | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to store the user consent for cookies in the category "Others". |
| cookielawinfo-checkbox-performance | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to store the user consent for cookies in the category "Performance". |
| CookieLawInfoConsent | 1 year | Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie. |
| elementor | never | This cookie is used by the website's WordPress theme. It allows the website owner to implement or change the website's content in real-time. |
| JSESSIONID | session | The JSESSIONID cookie is used by New Relic to store a session identifier so that New Relic can monitor session counts for an application. |
| viewed_cookie_policy | 1 year | The cookie is set by the GDPR Cookie Consent plugin to store whether or not the user has consented to the use of cookies. It does not store any personal data. |
| Cookie | Duration | Description |
|---|---|---|
| A3 | 1 year | No description |
| AnalyticsSyncHistory | 1 month | No description |
| citrix_ns_id_.d2d.gsa.gov__wlf | session | No description |
| citrix_ns_id_.gsa.gov__wlf | session | No description |
| li_gc | 5 months 27 days | No description |
| ln_or | 1 day | No description |
| m | 2 years | No description available. |
| NSC_IUUQ-Ebub2Efd | session | No description |
| SSESSe6f64672c023222bafbc47f83a5ecbd4 | 23 days 4 hours | No description |
| TS01c2db25 | session | No description |
| Cookie | Duration | Description |
|---|---|---|
| _fbp | 3 months | This cookie is set by Facebook to display advertisements when either on Facebook or on a digital platform powered by Facebook advertising, after visiting the website. |
| c | 1 year | This cookie is set by Rubicon Project to control synchronization of user identification and exchange of user data between various ad services. |
| CONSENT | 2 years | YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data. |
| fr | 3 months | Facebook sets this cookie to show relevant advertisements to users by tracking user behaviour across the web, on sites that have Facebook pixel or Facebook social plugin. |
| IDE | 1 year 24 days | Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile. |
| test_cookie | 15 minutes | The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies. |
| tuuid | 1 year | The tuuid cookie, set by BidSwitch, stores an unique ID to determine what adverts the users have seen if they have visited any of the advertiser's websites. The information is used to decide when and how often users will see a certain banner. |
| tuuid_lu | 1 year | This cookie, set by BidSwitch, stores a unique ID to determine what adverts the users have seen while visiting an advertiser's website. This information is then used to understand when and how often users will see a certain banner. |
| VISITOR_INFO1_LIVE | 5 months 27 days | A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface. |
| YSC | session | YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages. |
| yt-remote-connected-devices | never | YouTube sets this cookie to store the video preferences of the user using embedded YouTube video. |
| yt-remote-device-id | never | YouTube sets this cookie to store the video preferences of the user using embedded YouTube video. |
| yt.innertube::nextId | never | This cookie, set by YouTube, registers a unique ID to store data on what videos from YouTube the user has seen. |
| yt.innertube::requests | never | This cookie, set by YouTube, registers a unique ID to store data on what videos from YouTube the user has seen. |
| Cookie | Duration | Description |
|---|---|---|
| __hstc | 5 months 27 days | This is the main cookie set by Hubspot, for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session). |
| _ga | 2 years | The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors. |
| _ga_SQVZMMXYCW | 2 years | This cookie is installed by Google Analytics. |
| _gat_gtag_UA_88652169_15 | 1 minute | Set by Google to distinguish users. |
| _gat_UA-88652169-1 | 1 minute | A variation of the _gat cookie set by Google Analytics and Google Tag Manager to allow website owners to track visitor behaviour and measure site performance. The pattern element in the name contains the unique identity number of the account or website it relates to. |
| _gcl_au | 3 months | Provided by Google Tag Manager to experiment advertisement efficiency of websites using their services. |
| _gid | 1 day | Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously. |
| hubspotutk | 5 months 27 days | HubSpot sets this cookie to keep track of the visitors to the website. This cookie is passed to HubSpot on form submission and used when deduplicating contacts. |
| Cookie | Duration | Description |
|---|---|---|
| __cf_bm | 30 minutes | This cookie, set by Cloudflare, is used to support Cloudflare Bot Management. |
| __hssc | 30 minutes | HubSpot sets this cookie to keep track of sessions and to determine if HubSpot should increment the session number and timestamps in the __hstc cookie. |
| bcookie | 1 year | LinkedIn sets this cookie from LinkedIn share buttons and ad tags to recognize browser ID. |
| bscookie | 1 year | LinkedIn sets this cookie to store performed actions on the website. |
| lang | session | LinkedIn sets this cookie to remember a user's language setting. |
| lidc | 1 day | LinkedIn sets the lidc cookie to facilitate data center selection. |
| messagesUtk | 5 months 27 days | HubSpot sets this cookie to recognize visitors who chat via the chatflows tool. |
| tads_uid | 5 years | The domain of this cookie is owned by Technorati.This cookie helps the user to share pages through social networking sites. The main purpose of this cookie is advertising. |
| UserMatchHistory | 1 month | LinkedIn sets this cookie for LinkedIn Ads ID syncing. |




