








Road conditions in the United States are in steady decline, a point emphasized by the “D” grade they received in 2021’s American Society of Civil Engineers (ASCE) Infrastructure Report Card. Issues such as aging infrastructure, inadequate funding, and increasing traffic demands are major contributors to road deterioration and key drivers of innovation in this space.
A number of factors influence how quickly and to what degree road maintenance can be improved. One of the greatest challenges facing road managers today is being able to easily identify which roads need repairs and where those roads are located.
Current methods of assessing roads, even when following a standardized system, leave much to be desired. Advancements in technology like artificial intelligence (AI), and more specifically machine learning (ML), present opportunities to resolve these challenges and improve road assessment methods.
Since being developed at Carnegie Mellon University in 2016, RoadBotics by Michelin has used proprietary ML algorithms to assess over 49,000 miles of road, earning a reputation as a leader in automated road assessments.
Several road assessment methods exist and range from manual approaches to advanced high-tech solutions, and in some cases, no method at all. However, each of these methods has its limitations and inadequacies.
Many communities rely on manual inspections. Assessing roads using this approach consists of having a public works director or civil engineer visually inspect all roads in their community. Even for communities with small networks, these inspections are time consuming, subject to the engineer’s judgment, and prone to human error.
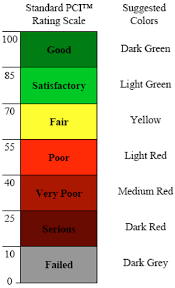
Using a standardized method of inspection offers opportunity for improvement, but often trades accuracy for speed. For example, the Pavement Condition Index (PCI), an accepted standardized method, relies on sampling small portions of a road network to make decisions regarding the entire network. This speeds up the assessment process, but sampling a non-representative section of road leads to misinformed maintenance strategies and missed opportunities for impactful repairs. Pavement Surface Evaluation and Rating (PASER) is yet another standard that exists, but like all other manual inspection methods, takes time to perform and training to perform correctly.
Unfortunately, the time-consuming and tedious nature of manual road assessments means most road owners do not have the time to assess all of their roads. This further perpetuates the use of sampling or multi-year gaps between assessments, despite the fact these lead to skewed results and poor use of maintenance budgets.
Many technology-assisted methods of road assessment that are capable of surveying an entire road network in a timely fashion require expensive equipment and extensive training. International Roughness Index (IRI), typically relies on an inertial measurement device attached to a vehicle to measure vertical movement of the vehicle as it travels over the road (i.e. the “roughness” of the road surface). This allows for faster assessments, but if the vehicle does not hit a pothole or other road distress, it is not detected. Alternatively, scanner vans use many sensors (LiDAR, radar, thermal cameras, high-precision GPS, etc.) to capture the state of road pavement. However, the format and sheer volume of data recorded requires special software and a trained professional to interpret it, not to mention the extra cost of outfitting and maintaining a vehicle with these expensive sensors.
In the absence of a fast-yet-cost-effective method for road assessments that does not sacrifice accuracy, many communities rely on a more reactive approach, fixing damages like alligator cracking or potholes, as they are reported. Unfortunately, once damage is severe enough to get the attention of the general public, it is often far more expensive to repair than if it was caught at the first sign of wear. In this way, poor road assessment methods can end up costing a community even more time and money.
RoadBotics by Michelin’s automated road assessment technology employs a strategic use of AI, specifically a computer vision-based deep learning ML model, to solve this problem.
Contrary to first impression, the intention is not to replace the engineer surveying the roads with a ML model. Instead, it seeks to apply years of research regarding the challenges facing road assessments to create a tool that makes road assessments less time-consuming and tedious.
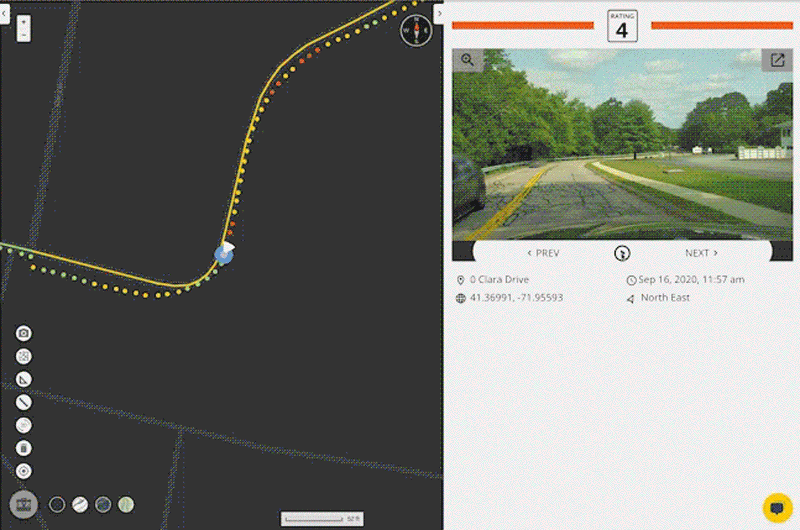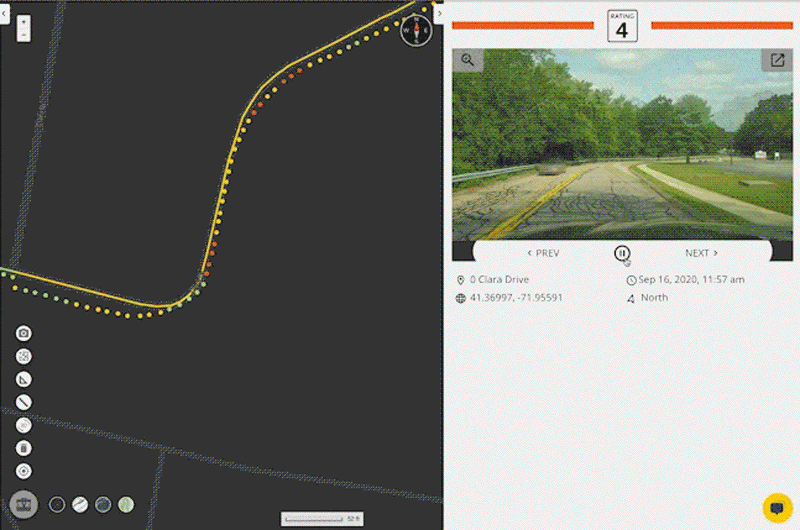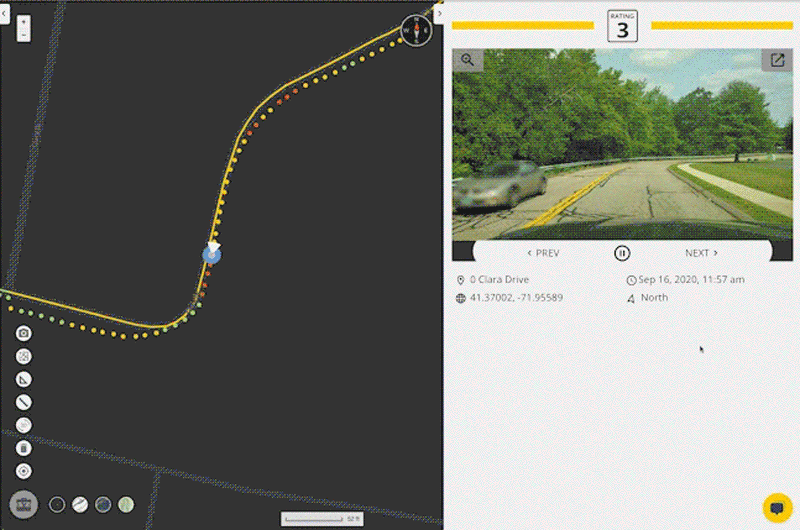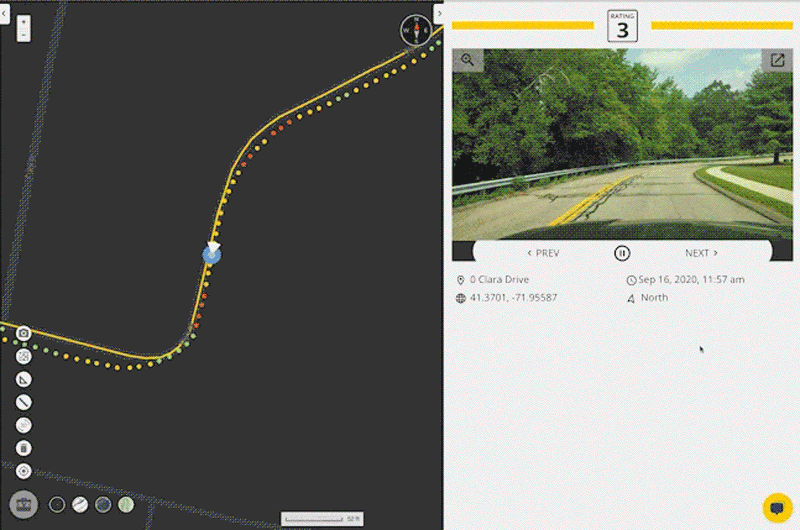
It starts with a convenient data collection process. A regular smartphone, mounted on the dashboard of any vehicle and running the RoadBotics data collection app, is used to record GPS and high-definition video data as a person drives down each road in the network being assessed.
This method of data collection allows for roads to be assessed at driving speeds – much faster than manual surveying and similar to scan-van data collection. It does not require any special equipment – just a smartphone to record the data and another to provide customized turn-by-turn directions.
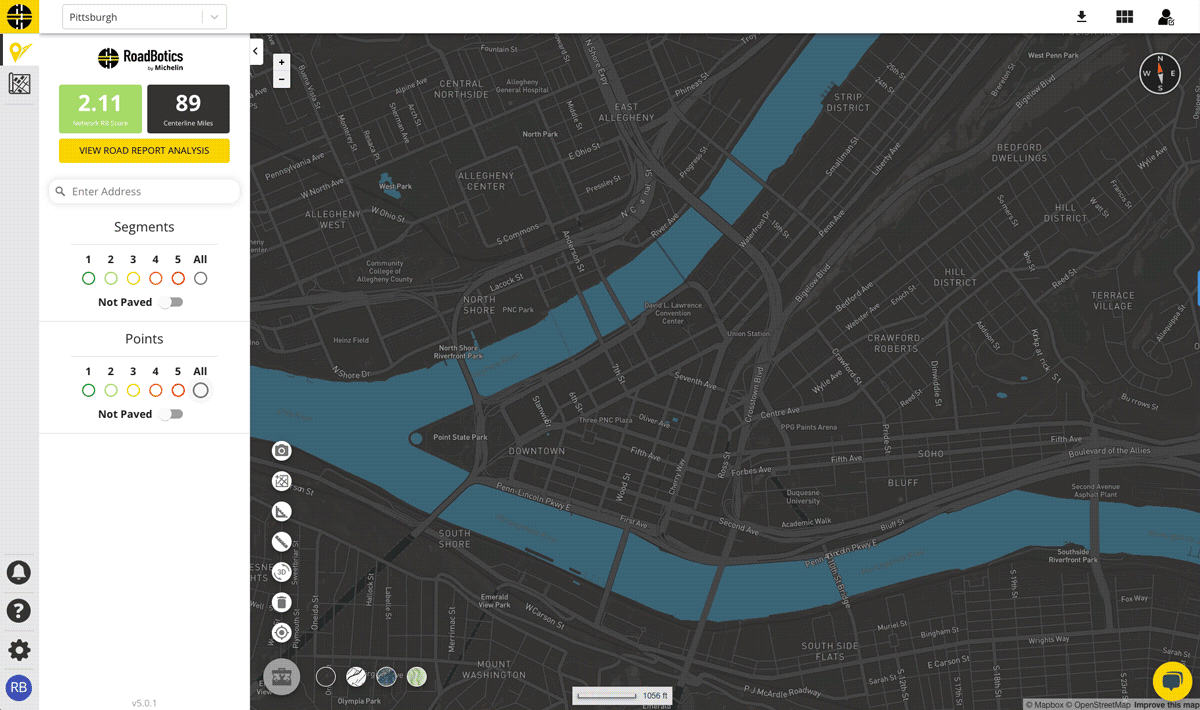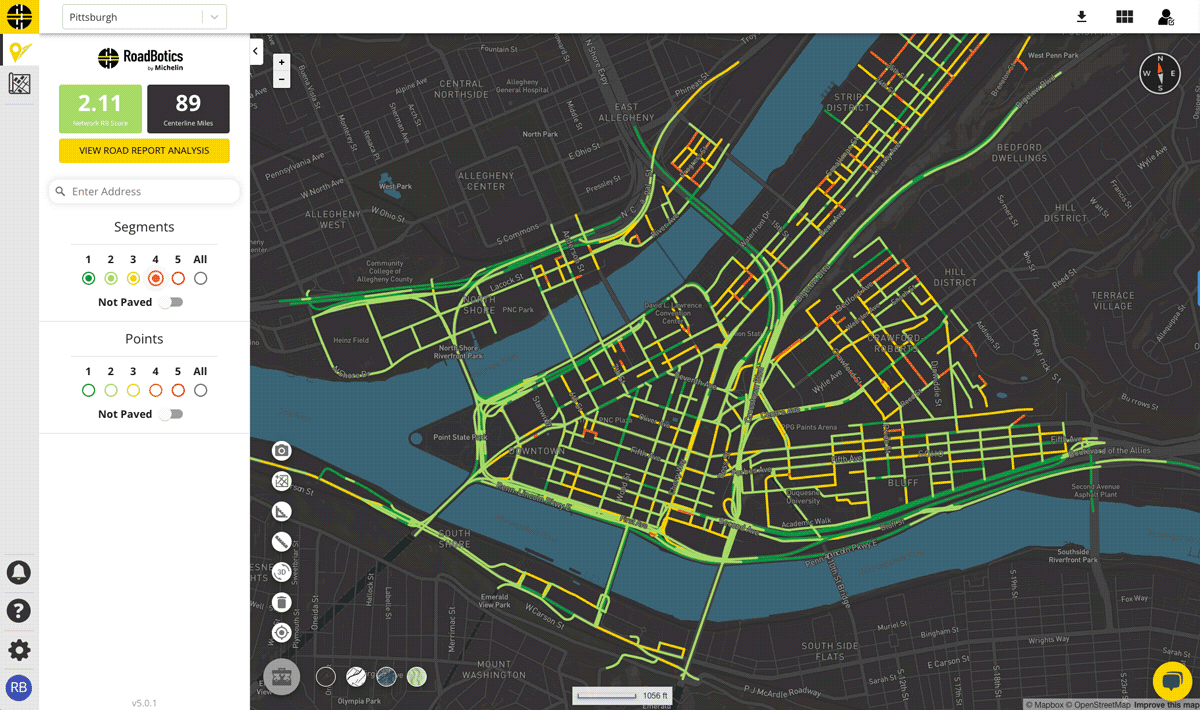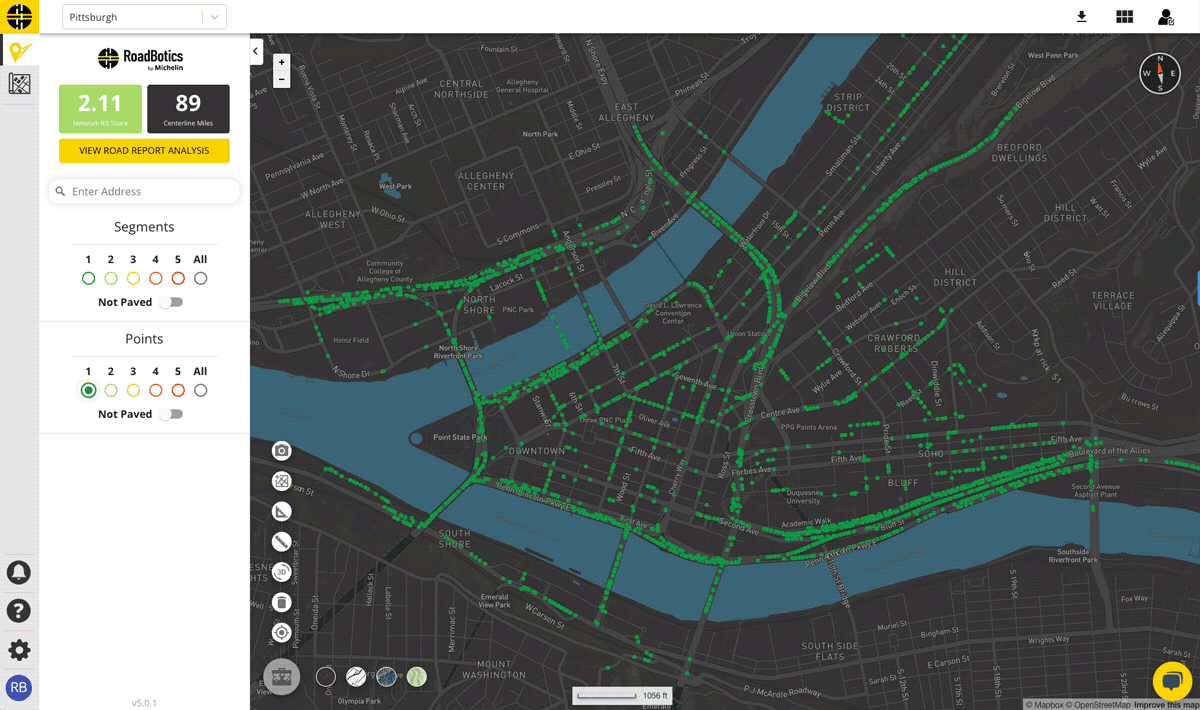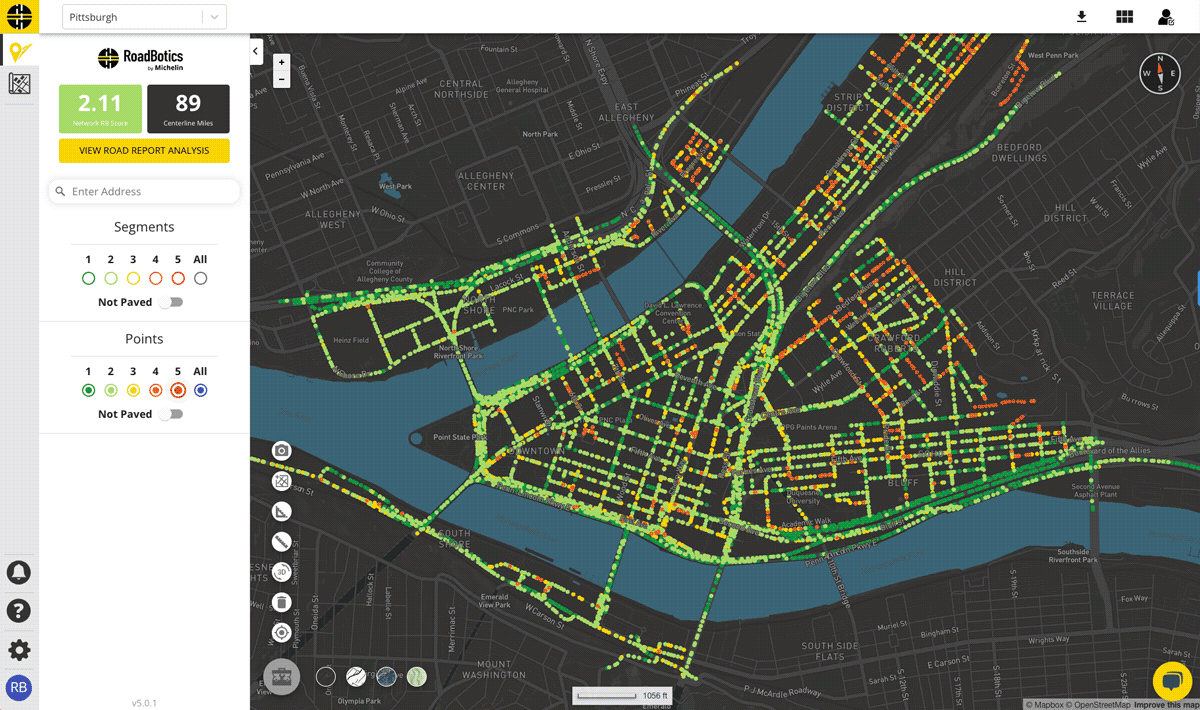
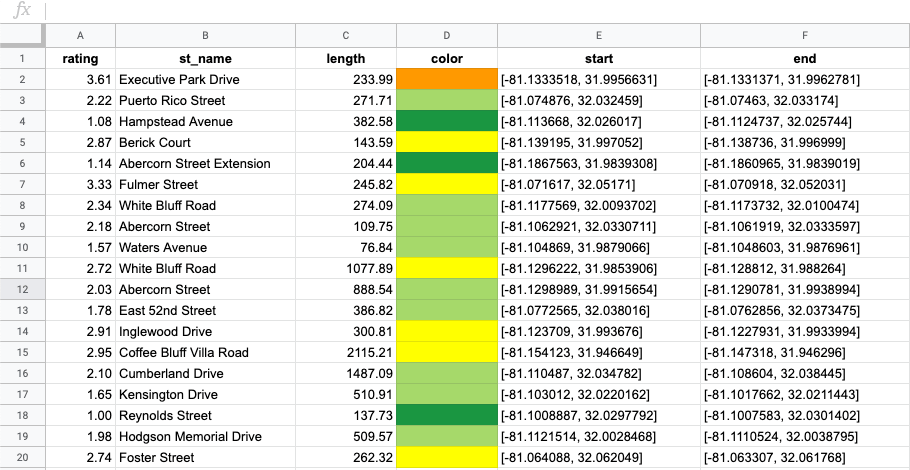
Once collection is complete, data is uploaded to a secure cloud platform. RoadBotics’ ML model categorizes each 10 foot section of road on a rating scale of 1 to 5. Sections rated a 1 are in perfect condition, and those rated a 5 are in the worst condition. The end product from an assessment is an interactive and color-coded map of roads and their ratings.
While this sounds great, many prospective clients ask how they can trust a deep learning model. More specifically, how does it determine a rating for each 10 foot section of road? Data scientists researching deep learning are well aware of the intricacies involved in addressing this particular question.To lend some perspective, there is an entire field dedicated to active research focused on developing deep learning models specifically to offer explanations for their reasoning.
So how can such a model be trusted to provide accurate road assessments if it cannot tell us how it makes the assessment? First, when developing ML models, RoadBotics by Michelin uses standard methods in machine learning to check performance. Second, they compare its performance to that of humans on the same task. This second step points to a, perhaps, uncomfortable truth: humans are not perfect. But it reveals that an ML model does not need to be perfect to be helpful in making the work easier and more efficient. If it helps civil engineers focus their valuable time and attention on the roads that need it most, it is a net gain.
After training was complete, they tested the model using the test set to determine performance. As is standard in machine learning, they used a confusion matrix, as well as precision and recall to quantify model performance.
A confusion matrix is a square matrix where the ground-truth classification for a set of data is plotted along one axis and the model’s predicted classification for that data is plotted along the other axis. Each location of the confusion matrix counts the number (or proportion) of instances in the data that fall into each category. Here is what a confusion matrix for a binary classification (i.e. true or false) looks like:
By analyzing the values in the confusion matrix, various performance metrics can be calculated, such as:
These metrics, along with the confusion matrix, are regularly used in data science and ML to determine an algorithm’s performance and diagnose problems during development. In most cases, the goal is to minimize both false positives and false negatives. This helps to achieve a well-balanced and reliable model that accurately classifies real-world data.
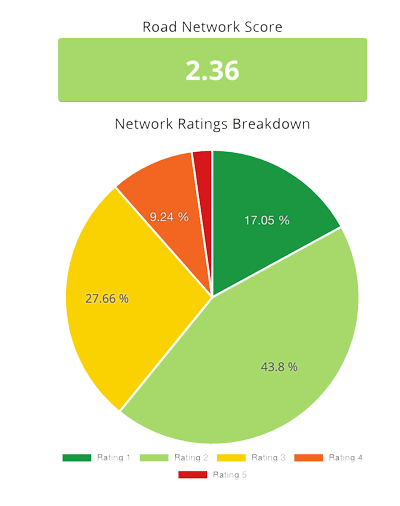
When looking at these metrics, as well as how often RoadBotics’ ML model’s ratings were off by 1, 2, 3, or 4 from the ground truth, they found that the model is able to perform better than the individual experts did in their study mentioned earlier. To provide an additional level of certainty, they tested their model on data that was not yet available during the time it was developed.
This is the ultimate test of real-world performance. The model’s performance metrics were as good as those of the experts from their study, and in some cases were even better.
While a granular view of roads can be helpful, more data is not always better. Beyond a certain point, it is unlikely that a higher volume of data will lead to different final decisions. It is important to consider this reality when creating technology to improve road assessment methods. Road managers do not repair their roads in 10-foot sections since the time, effort, and money required to perform maintenance is more efficiently used by working on larger sections of road. Using their proprietary AI, RoadBotics by Michelin ensures a thorough assessment through rating every 10 feet of road, but does not overlook how maintenance is executed in the real-world.
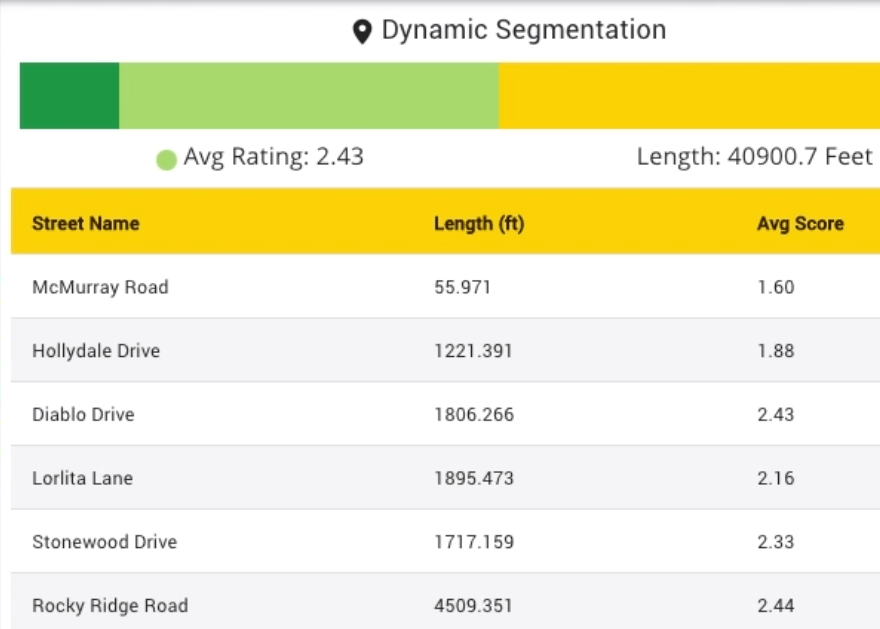
They provide an aggregate rating and other statistics for individual roads based on the assessments for each 10-foot section that make up any given road. Aggregating the data leads to even more accurate results at a resolution that road managers can take action on.
As alluded to near the beginning, machine learning models, and AI in general, are not meant to replace humans. It is meant to be a useful tool that people can trust. RoadBotics by Michelin doesn’t simply run their model and then call it a day. They have a team of people check the output of their model and occasionally make minor adjustments before delivering the final ratings to customers. This confirms their clients get accurate assessments, while creating the new data to maintain and improve their model over time.
Not to mention, the ratings themselves are not the final say. The ratings they generate are meant to help road managers focus their attention on the areas of their network that need it most.
With 4 million roads to manage in the United States, checking every one of them regularly to find the exact spots needing attention is not possible through human effort alone.
Using AI, RoadBotics by Michelin can give communities an overall view of their entire road network conditions and make pavement maintenance planning a proactive process, stopping potholes and other severe damage from forming in the first place.

© 2024 RoadBotics, Inc | 322 North Shore Drive, Suite 200, Pittsburgh, PA 15212
| Cookie | Duration | Description |
|---|---|---|
| __hssrc | session | This cookie is set by Hubspot whenever it changes the session cookie. The __hssrc cookie set to 1 indicates that the user has restarted the browser, and if the cookie does not exist, it is assumed to be a new session. |
| _GRECAPTCHA | 5 months 27 days | This cookie is set by the Google recaptcha service to identify bots to protect the website against malicious spam attacks. |
| ak_bmsc | 2 hours | This cookie is used by Akamai to optimize site security by distinguishing between humans and bots |
| citrix_ns_id | session | This cookie is set by the provider Citrix, a web application firewall. This cookie is used for protecting the website against known and unknown attacks. |
| cookielawinfo-checkbox-advertisement | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category . |
| cookielawinfo-checkbox-analytics | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Analytics" category . |
| cookielawinfo-checkbox-functional | 1 year | The cookie is set by the GDPR Cookie Consent plugin to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Necessary" category . |
| cookielawinfo-checkbox-others | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to store the user consent for cookies in the category "Others". |
| cookielawinfo-checkbox-performance | 1 year | Set by the GDPR Cookie Consent plugin, this cookie is used to store the user consent for cookies in the category "Performance". |
| CookieLawInfoConsent | 1 year | Records the default button state of the corresponding category & the status of CCPA. It works only in coordination with the primary cookie. |
| elementor | never | This cookie is used by the website's WordPress theme. It allows the website owner to implement or change the website's content in real-time. |
| JSESSIONID | session | The JSESSIONID cookie is used by New Relic to store a session identifier so that New Relic can monitor session counts for an application. |
| viewed_cookie_policy | 1 year | The cookie is set by the GDPR Cookie Consent plugin to store whether or not the user has consented to the use of cookies. It does not store any personal data. |
| Cookie | Duration | Description |
|---|---|---|
| A3 | 1 year | No description |
| AnalyticsSyncHistory | 1 month | No description |
| citrix_ns_id_.d2d.gsa.gov__wlf | session | No description |
| citrix_ns_id_.gsa.gov__wlf | session | No description |
| li_gc | 5 months 27 days | No description |
| ln_or | 1 day | No description |
| m | 2 years | No description available. |
| NSC_IUUQ-Ebub2Efd | session | No description |
| SSESSe6f64672c023222bafbc47f83a5ecbd4 | 23 days 4 hours | No description |
| TS01c2db25 | session | No description |
| Cookie | Duration | Description |
|---|---|---|
| _fbp | 3 months | This cookie is set by Facebook to display advertisements when either on Facebook or on a digital platform powered by Facebook advertising, after visiting the website. |
| c | 1 year | This cookie is set by Rubicon Project to control synchronization of user identification and exchange of user data between various ad services. |
| CONSENT | 2 years | YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data. |
| fr | 3 months | Facebook sets this cookie to show relevant advertisements to users by tracking user behaviour across the web, on sites that have Facebook pixel or Facebook social plugin. |
| IDE | 1 year 24 days | Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile. |
| test_cookie | 15 minutes | The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies. |
| tuuid | 1 year | The tuuid cookie, set by BidSwitch, stores an unique ID to determine what adverts the users have seen if they have visited any of the advertiser's websites. The information is used to decide when and how often users will see a certain banner. |
| tuuid_lu | 1 year | This cookie, set by BidSwitch, stores a unique ID to determine what adverts the users have seen while visiting an advertiser's website. This information is then used to understand when and how often users will see a certain banner. |
| VISITOR_INFO1_LIVE | 5 months 27 days | A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface. |
| YSC | session | YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages. |
| yt-remote-connected-devices | never | YouTube sets this cookie to store the video preferences of the user using embedded YouTube video. |
| yt-remote-device-id | never | YouTube sets this cookie to store the video preferences of the user using embedded YouTube video. |
| yt.innertube::nextId | never | This cookie, set by YouTube, registers a unique ID to store data on what videos from YouTube the user has seen. |
| yt.innertube::requests | never | This cookie, set by YouTube, registers a unique ID to store data on what videos from YouTube the user has seen. |
| Cookie | Duration | Description |
|---|---|---|
| __hstc | 5 months 27 days | This is the main cookie set by Hubspot, for tracking visitors. It contains the domain, initial timestamp (first visit), last timestamp (last visit), current timestamp (this visit), and session number (increments for each subsequent session). |
| _ga | 2 years | The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors. |
| _ga_SQVZMMXYCW | 2 years | This cookie is installed by Google Analytics. |
| _gat_gtag_UA_88652169_15 | 1 minute | Set by Google to distinguish users. |
| _gat_UA-88652169-1 | 1 minute | A variation of the _gat cookie set by Google Analytics and Google Tag Manager to allow website owners to track visitor behaviour and measure site performance. The pattern element in the name contains the unique identity number of the account or website it relates to. |
| _gcl_au | 3 months | Provided by Google Tag Manager to experiment advertisement efficiency of websites using their services. |
| _gid | 1 day | Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously. |
| hubspotutk | 5 months 27 days | HubSpot sets this cookie to keep track of the visitors to the website. This cookie is passed to HubSpot on form submission and used when deduplicating contacts. |
| Cookie | Duration | Description |
|---|---|---|
| __cf_bm | 30 minutes | This cookie, set by Cloudflare, is used to support Cloudflare Bot Management. |
| __hssc | 30 minutes | HubSpot sets this cookie to keep track of sessions and to determine if HubSpot should increment the session number and timestamps in the __hstc cookie. |
| bcookie | 1 year | LinkedIn sets this cookie from LinkedIn share buttons and ad tags to recognize browser ID. |
| bscookie | 1 year | LinkedIn sets this cookie to store performed actions on the website. |
| lang | session | LinkedIn sets this cookie to remember a user's language setting. |
| lidc | 1 day | LinkedIn sets the lidc cookie to facilitate data center selection. |
| messagesUtk | 5 months 27 days | HubSpot sets this cookie to recognize visitors who chat via the chatflows tool. |
| tads_uid | 5 years | The domain of this cookie is owned by Technorati.This cookie helps the user to share pages through social networking sites. The main purpose of this cookie is advertising. |
| UserMatchHistory | 1 month | LinkedIn sets this cookie for LinkedIn Ads ID syncing. |




